Method
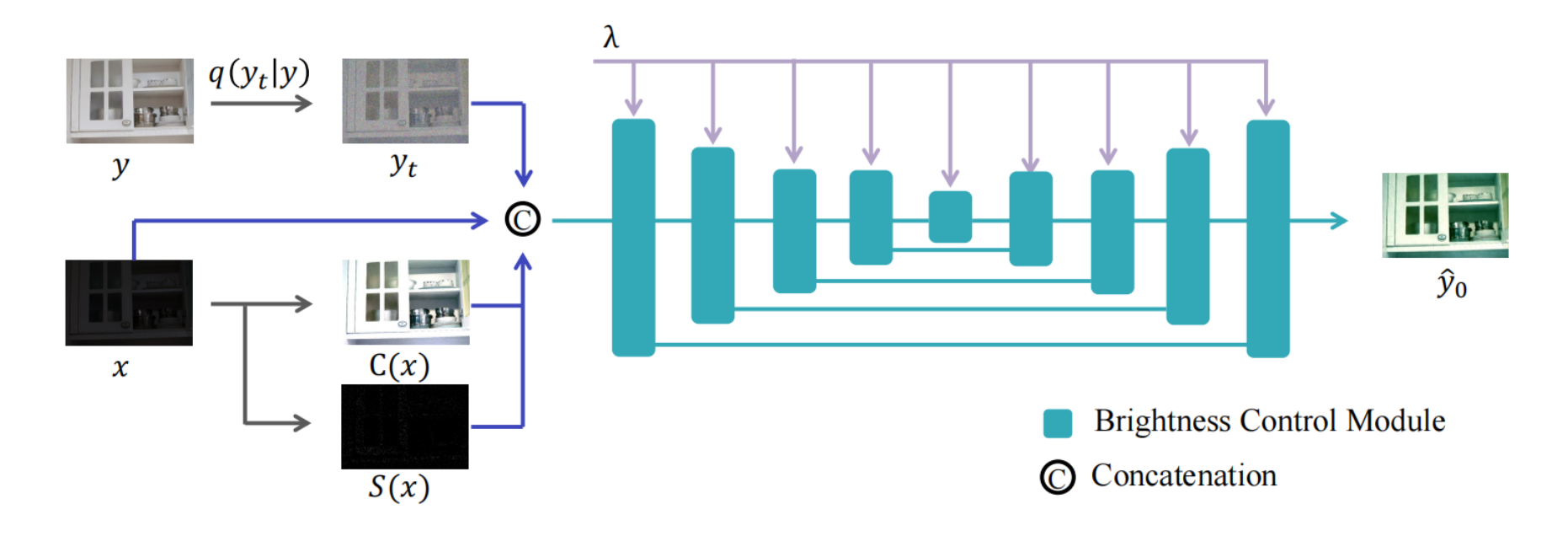
During training, we randomly sample a pair of low-light image `x` and normal-light image `y`. We then construct `y_t`, color map `C(x)`, and snr map `S(x)` as additional inputs to the diffusion model. We extract brightness level `\lambda` of normal-light image by cacluating the average pixel value. Then `\lambda` is injected into the Brightness Control Modules to enable seamless and consistent brightness control. Alongside $L_\text{simple}$, we introduce auxiliary losses on the denoised estimate `\hat{y_0}` to provide better supervision for the model.
To achieve regional controllability, We incorporate a binary mask `M` into our diffusion model by concatenating the mask with the original inputs. To accommodate this requirement, we created synthetic training data by randomly sampling free-form masks with feathered boundaries. The target images are generated by alpha blending the low-light and normal-light images from existing low-light datasets.

The sampling process is implemented with DDIM sampler. We use classifier free guide method to estimate two noise from a conditional model and a unconditional model. Armed with SAM, CLE Diffusion achieve light enhancement with specified regions and designated levels of brightness.
Qualitative Results
Visual Results

Figure 1: CLE Diffusion enables users to select regions of interest(ROI) with a simple click and adjust the degree of brightness enhancement as desired, while MAXIM [1] is limited to homogeneously enhancing images to a pre-defined level of brightness.

Figure 2: More cases about region controllable light enhancement. Equipped with the Segment-Anything Model (SAM), users can designate regions of interest (ROI) using simple inputs like points or boxes. Our model facilitates controllable light enhancement within these regions, producing results that blend naturally and seamlessly with the surrounding environment.

Figure 3: Visual results of global brightness control on LOL dataset. By adjusting the brightness levels during inference, we can sample images with varying degrees of brightness while maintaining high image quality

Figure 4: Global Controllable Light Enhancement on MIT-Adobe FiveK dataset. Our method enables users to select various brightness levels, even significantly brighter than the ground truth.

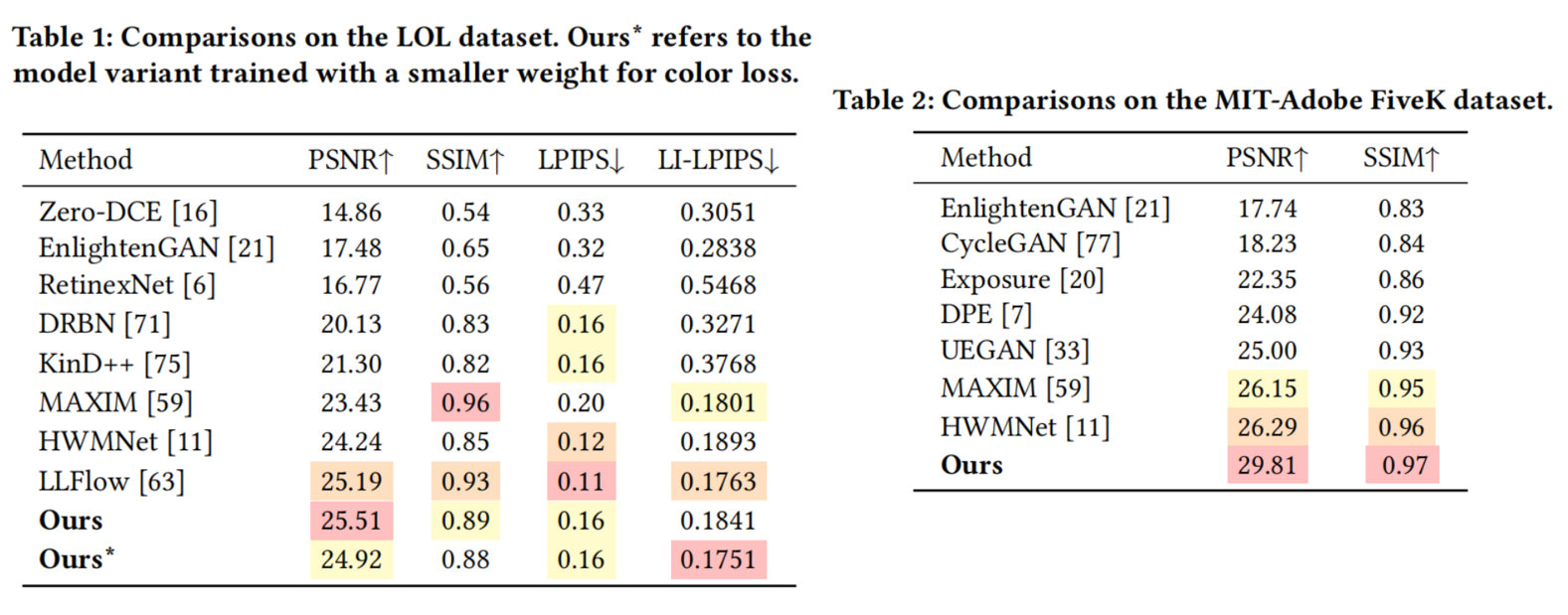
Figure 5: Results on LOL [2] test dataset. Our result exhibits fewer artifacts and is more consistent with the ground truth image.

Figure 6: Results on MIT-Adobe FiveK [3] test dataset. Our result exhibits less color distortion and contains richer details, which are more consistent with the ground truth.

Figure 7: Comparisons on a real-world image from VE-LOL dataset [4]. Other methods often rely on well-lit brightness extracted from pre-existing datasets, limiting their applicability to diverse scenarios. Unlike most methods that struggle to enhance the brightness at night sufficiently, our method incorporates a brightness control module, allowing us to sample images with higher brightness that appear more natural in such situations.

Figure 8: Performance on normal light image inputs. We utilize the normal-light images from the LOL dataset as inputs to evaluate the models’ capability in handling high-light images. HWMNet and MAXIM exhibit overexposure in certain regions, resulting in considerably over-exposed images. LLFlow produces blurred images, while other methods result in color distortion. Our method achieves visually pleasing results in terms of color and brightness.

Figure 9: Global brightness control compared with ReCoRo [5]. While ReCoRo is constrained to enhancing images with brightness levels that fall between low-light and “well-lit” images, our model can handle a wider range of brightness levels. It can be adjusted to sample any desired brightness, providing greater flexibility and control over different lighting conditions.
